Video Super-Resolution Transformer
方法:
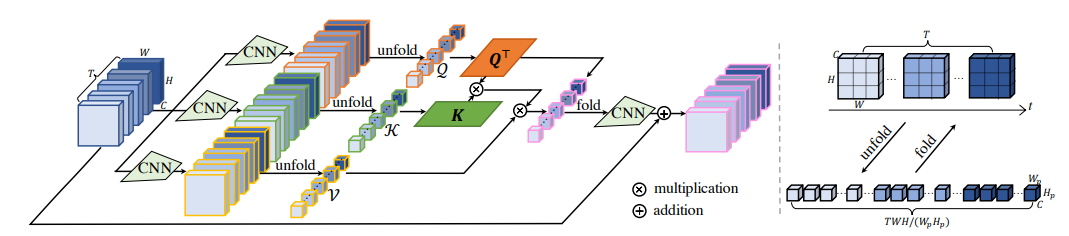
每一帧都用卷积提取特征,(放于 batch 中独立进行),所有输入帧都进行 unfold 操作得到 TWH/(WpHp) 个小 patch 视为 token,计算这些小 patch 之间的 attention。
输入5连续帧,先提取特征
Transformer + Bi flow
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class Transformer(nn.Module):
def __init__(self, num_feat, feat_size, depth, patch_size, heads):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual(PreNorm(num_feat, feat_size, globalAttention(num_feat, patch_size, heads))),
Residual(PreNorm(num_feat, feat_size, FeedForward(num_feat)))
]))
def forward(self, x, lrs=None, flows=None):
for attn, ff in self.layers:
x = attn(x)
x = ff(x, lrs=lrs, flows=flows)
return x由 Transformer 类实现,每层经过一个transformer,layer Norm,冗余层:
1
Residual(PreNorm(num_feat, feat_size, globalAttention(num_feat, patch_size, heads)))
分析
globalAttention, 在这个模块中,输入(B*(T=5)*C*64*64)被切为 Patch_size 大小(8*8)的块,一共有5 * 8 * 8个1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41class globalAttention(nn.Module):
def __init__(self, num_feat=64, patch_size=8, heads=1):
super(globalAttention, self).__init__()
self.heads = heads
self.dim = patch_size ** 2 * num_feat
self.hidden_dim = self.dim // heads
self.num_patch = (64 // patch_size) ** 2
self.to_q = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1, groups=num_feat)
self.to_k = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1, groups=num_feat)
self.to_v = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1)
self.conv = nn.Conv2d(in_channels=num_feat, out_channels=num_feat, kernel_size=3, padding=1)
self.feat2patch = torch.nn.Unfold(kernel_size=patch_size, padding=0, stride=patch_size)
self.patch2feat = torch.nn.Fold(output_size=(64, 64), kernel_size=patch_size, padding=0, stride=patch_size)
def forward(self, x):
b, t, c, h, w = x.shape # B, 5, 64, 64, 64
H, D = self.heads, self.dim
n, d = self.num_patch, self.hidden_dim
q = self.to_q(x.view(-1, c, h, w)) # [B*5, 64, 64, 64]
k = self.to_k(x.view(-1, c, h, w)) # [B*5, 64, 64, 64]
v = self.to_v(x.view(-1, c, h, w)) # [B*5, 64, 64, 64]
unfold_q = self.feat2patch(q) # [B*5, 8*8*64, 8*8]
unfold_k = self.feat2patch(k) # [B*5, 8*8*64, 8*8]
unfold_v = self.feat2patch(v) # [B*5, 8*8*64, 8*8]
unfold_q = unfold_q.view(b, t, H, d, n) # [B, 5, H, 8*8*64/H, 8*8]
unfold_k = unfold_k.view(b, t, H, d, n) # [B, 5, H, 8*8*64/H, 8*8]
unfold_v = unfold_v.view(b, t, H, d, n) # [B, 5, H, 8*8*64/H, 8*8]
unfold_q = unfold_q.permute(0, 2, 3, 1, 4).contiguous() # [B, H, 8*8*64/H, 5, 8*8]
unfold_k = unfold_k.permute(0, 2, 3, 1, 4).contiguous() # [B, H, 8*8*64/H, 5, 8*8]
unfold_v = unfold_v.permute(0, 2, 3, 1, 4).contiguous() # [B, H, 8*8*64/H, 5, 8*8]
unfold_q = unfold_q.view(b, H, d, t * n) # [B, H, 8*8*64/H, 5*8*8]
unfold_k = unfold_k.view(b, H, d, t * n) # [B, H, 8*8*64/H, 5*8*8]
unfold_v = unfold_v.view(b, H, d, t * n) # [B, H, 8*8*64/H, 5*8*8]注意,
Unfold提取的滑动窗口是堆在8*8*64/H维度的。5*8*8指的是各个窗口。我们需要计算各个窗口之间的 attention。这个注意力是包含了5帧之间的注意力,不仅仅是1
2
3
4
5
6
7
8
9
10
11
12
13
14attn = torch.matmul(unfold_q.transpose(2, 3), unfold_k) # [B, H, 5*8*8, 5*8*8]
attn = attn * (d ** (-0.5)) # [B, H, 5*8*8, 5*8*8]
attn = F.softmax(attn, dim=-1) # [B, H, 5*8*8, 5*8*8]
attn_x = torch.matmul(attn, unfold_v.transpose(2, 3)) # [B, H, 5*8*8, 8*8*64/H]
attn_x = attn_x.view(b, H, t, n, d) # [B, H, 5, 8*8, 8*8*64/H]
attn_x = attn_x.permute(0, 2, 1, 4, 3).contiguous() # [B, 5, H, 8*8*64/H, 8*8]
attn_x = attn_x.view(b * t, D, n) # [B*5, 8*8*64, 8*8]
feat = self.patch2feat(attn_x) # [B*5, 64, 64, 64]
out = self.conv(feat).view(x.shape) # [B, 5, 64, 64, 64]
out += x # [B, 5, 64, 64, 64]
return out
Bi flow,这里会用到已经计算好的光流作为输入 :
1
Residual(PreNorm(num_feat, feat_size, FeedForward(num_feat)))
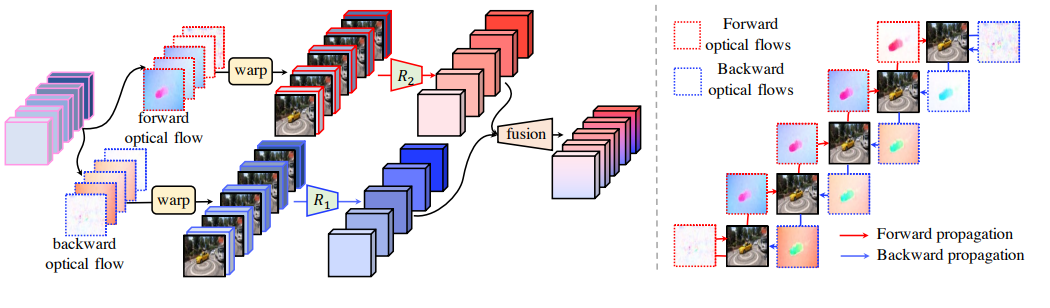
这里使用了首帧和首帧,尾帧和尾帧的 identity 光流来获得相同尺寸的特征。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
class FeedForward(nn.Module):
def __init__(self, num_feat):
super().__init__()
self.backward_resblocks = ResidualBlocksWithInputConv(num_feat + 3, num_feat, num_blocks=30)
self.forward_resblocks = ResidualBlocksWithInputConv(num_feat + 3, num_feat, num_blocks=30)
self.fusion = nn.Conv2d(num_feat * 2, num_feat, 1, 1, 0, bias=True)
self.lrelu = nn.LeakyReLU(negative_slope=0.1, inplace=True)
def forward(self, x, lrs=None, flows=None):
b, t, c, h, w = x.shape
x1 = torch.cat([x[:, 1:, :, :, :], x[:, -1, :, :, :].unsqueeze(1)], dim=1) # [B, 5, 64, 64, 64]
flow1 = flows[1].contiguous().view(-1, 2, h, w).permute(0, 2, 3, 1) # [B*5, 64, 64, 2]
x1 = flow_warp(x1.view(-1, c, h, w), flow1) # [B*5, 64, 64, 64]
x1 = torch.cat([lrs.view(b * t, -1, h, w), x1], dim=1) # [B*5, 67, 64, 64]
x1 = self.backward_resblocks(x1) # [B*5, 64, 64, 64]
x2 = torch.cat([x[:, 0, :, :, :].unsqueeze(1), x[:, :-1, :, :, :]], dim=1) # [B, 5, 64, 64, 64]
flow2 = flows[0].contiguous().view(-1, 2, h, w).permute(0, 2, 3, 1) # [B*5, 64, 64, 2]
x2 = flow_warp(x2.view(-1, c, h, w), flow2) # [B*5, 64, 64, 64]
x2 = torch.cat([lrs.view(b * t, -1, h, w), x2], dim=1) # [B*5, 67, 64, 64]
x2 = self.forward_resblocks(x2) # [B*5, 64, 64, 64]
# fusion the backward and forward features
out = torch.cat([x1, x2], dim=1) # [B*5, 128, 64, 64]
out = self.lrelu(self.fusion(out)) # [B*5, 64, 64, 64]
out = out.view(x.shape) # [B, 5, 64, 64, 64]
return out
关于数据流,在训练过程中,有些 tensor 需要 64 大小,这对各种尺寸的输入图像不适应,所以在源码中,作者 crop 了大于 64 的 图片,将整个图片定在 64 大小, patch 之间存在 overlap 。
存在尺寸写死的地方有:
layer_norm的地方,需要提供 tensor 的 size ,我们使用nn.functional.layer_norm(x, x.size()[1:])可以避免GlobalAttention中的unfold和fold中,由于图像的大小不能被patch_size整除,且作者将大小写死torch.nn.Fold(output_size=(64, 64),...)我们先将输入 pad 到合适大小然后进行操作。1
2
3feat = torch.nn.functional.fold(attn_x, output_size=(h, w),
kernel_size=self.patch_size, padding=0,
stride=self.patch_size)pad 后的特征会比之前大,在返回的时候需要裁剪
out_nopad = out[:, :, :, pad_len_h:h-pad_len_h, pad_len_w:w-pad_len_w]
1
2
3
4
5
6
7
8
9
10
11
12
13def test(self):
self.net_g.eval()
with torch.no_grad():
if self.opt['crop']:
# if self.opt['train'].get('flow_opt'):
# self.output = forward_crop(self.lq, self.net_g, flow_opt=self.opt['train'].get('flow_opt'))
# else:
if 'train' in self.opt['datasets']:
lq_size = self.opt['datasets']['train']['gt_size'] // 4
if 'test' in self.opt['datasets']:
lq_size = self.opt['datasets']['test']['lq_size']
overlap = lq_size // 2 # TODO
self.output = forward_crop(self.lq, self.net_g, lq_size=lq_size, overlap=overlap)
裁剪方法如下,将所有的图片裁剪成:
1 | def forward_crop(x, model, lq_size=64, scale=4, overlap=16, flow_opt=False): |